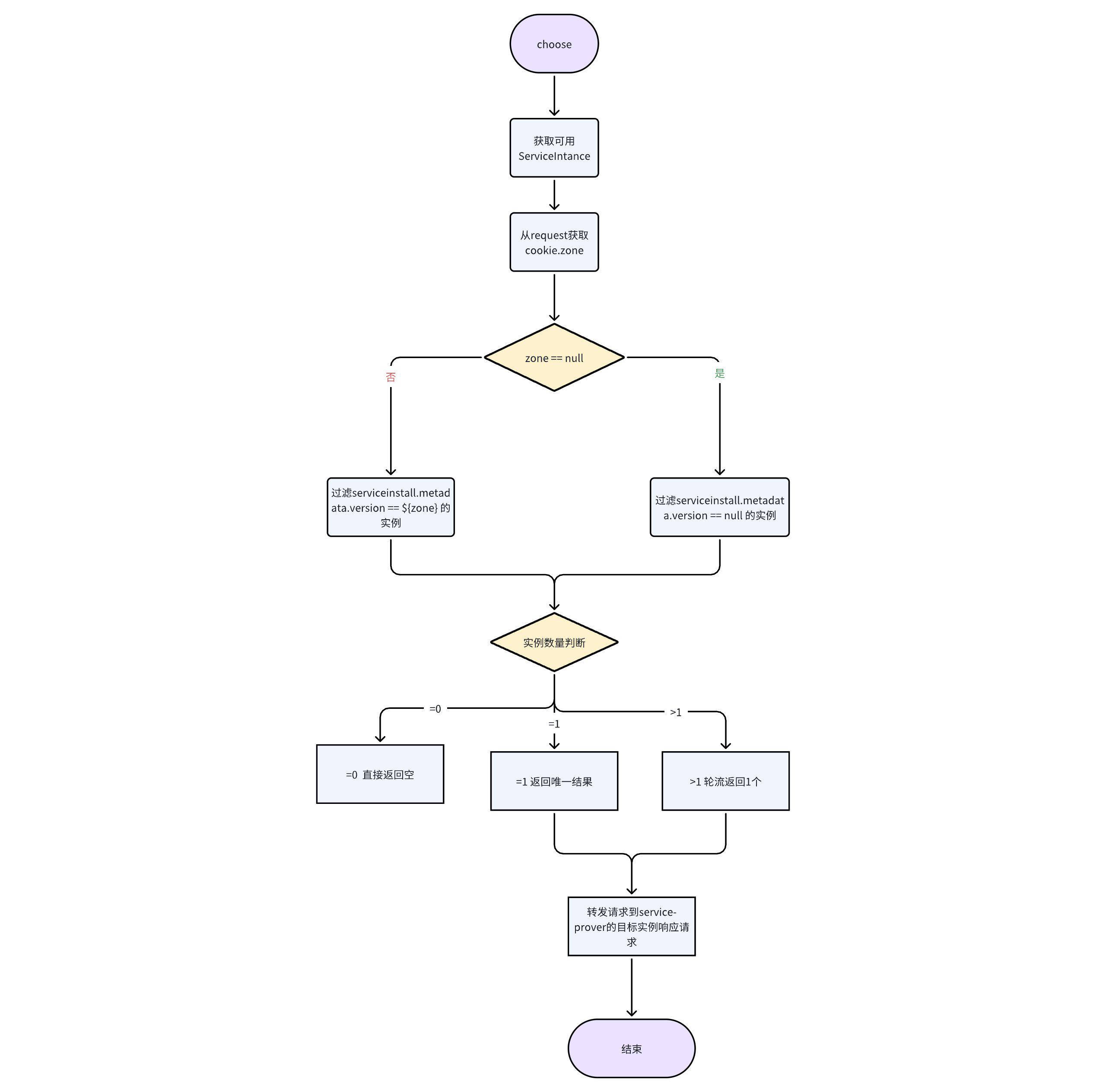
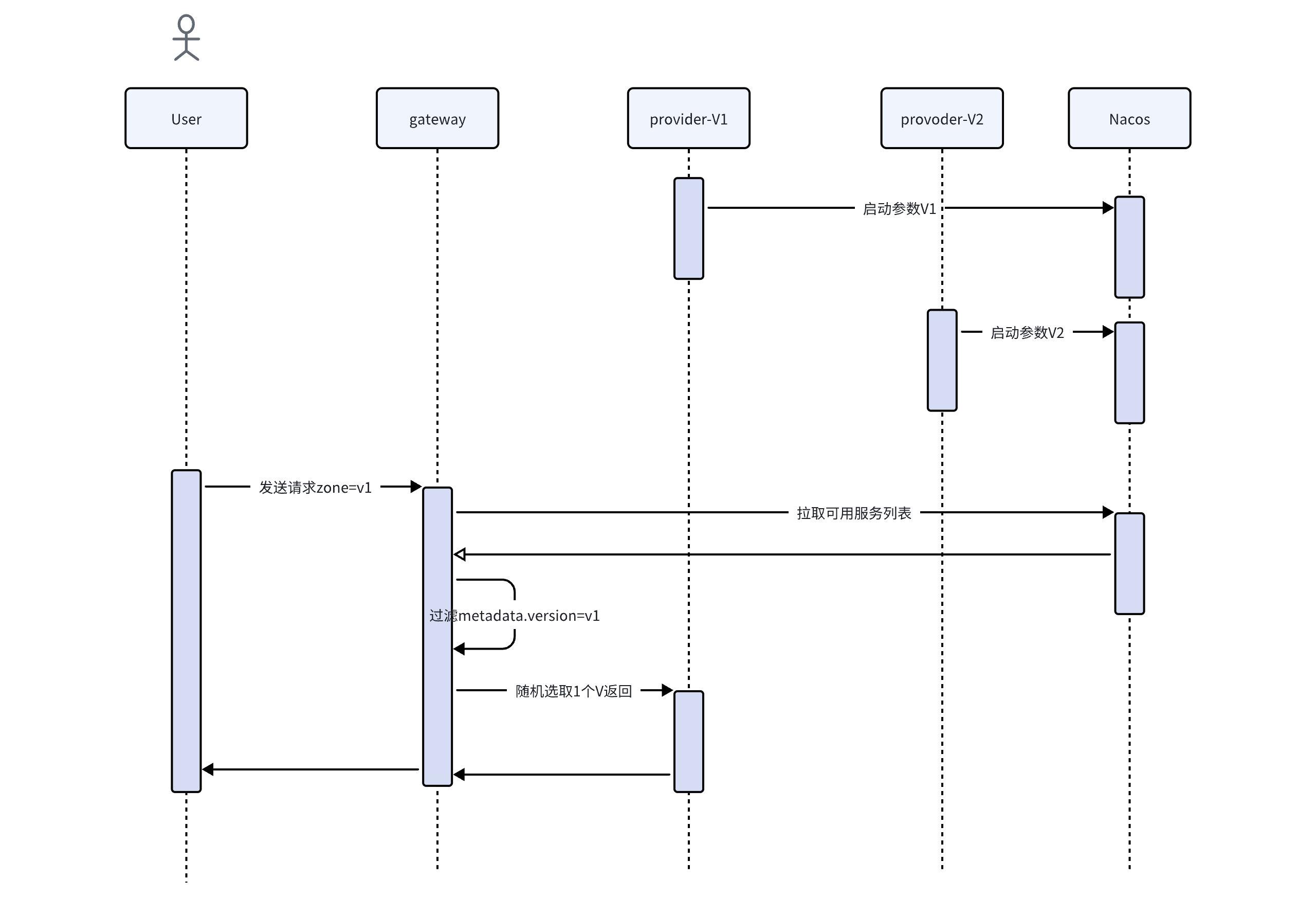
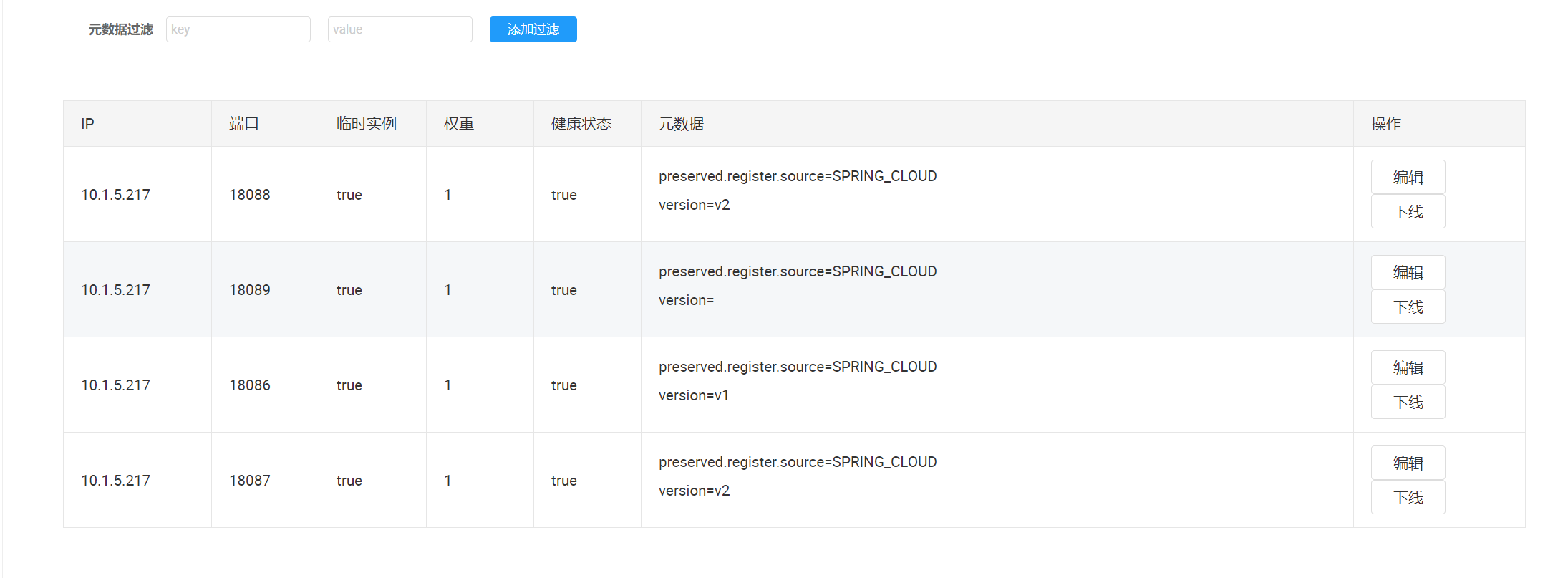
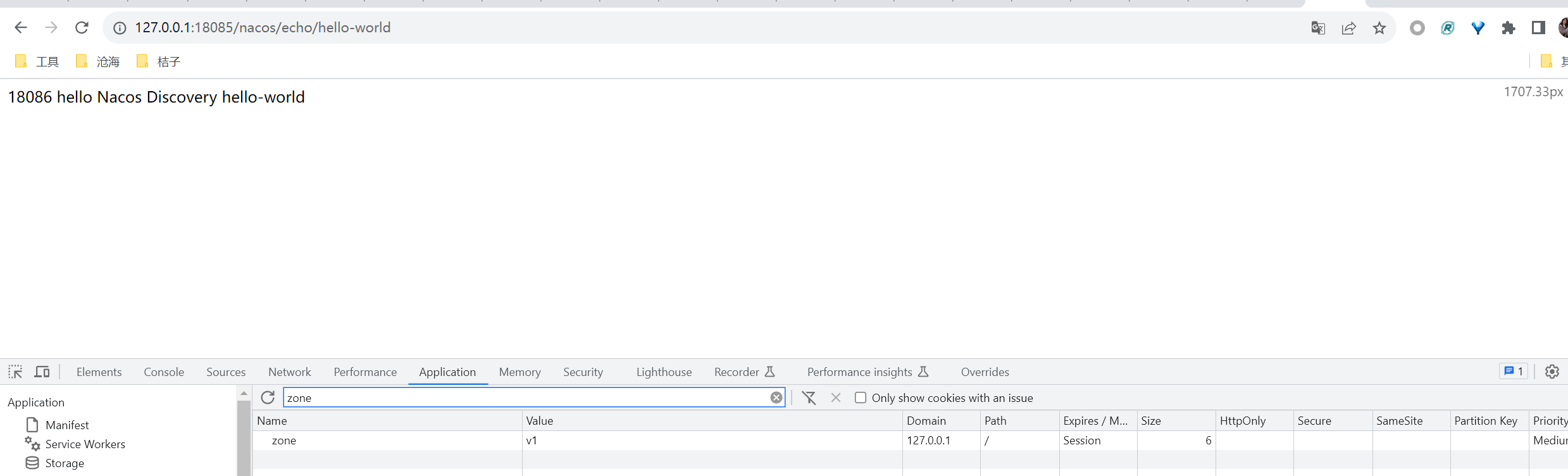
SpringCloud配置中心优先级
SpringCloud 配置中心优先级
01.02-SpringCloud 配置中心优先级
1. springboot 的配置优先级
命令行参数 > 操作系统环境变量 > 应用外的配置文件 > 应用内的配置文件
这里命令行参数设置的优先级是最高的,方便部署不同环境。
2. 加入 springcloud 配置中心后
加入 springcloud 的配置中心后,优先级并不是想象中的命令行最高优先级。
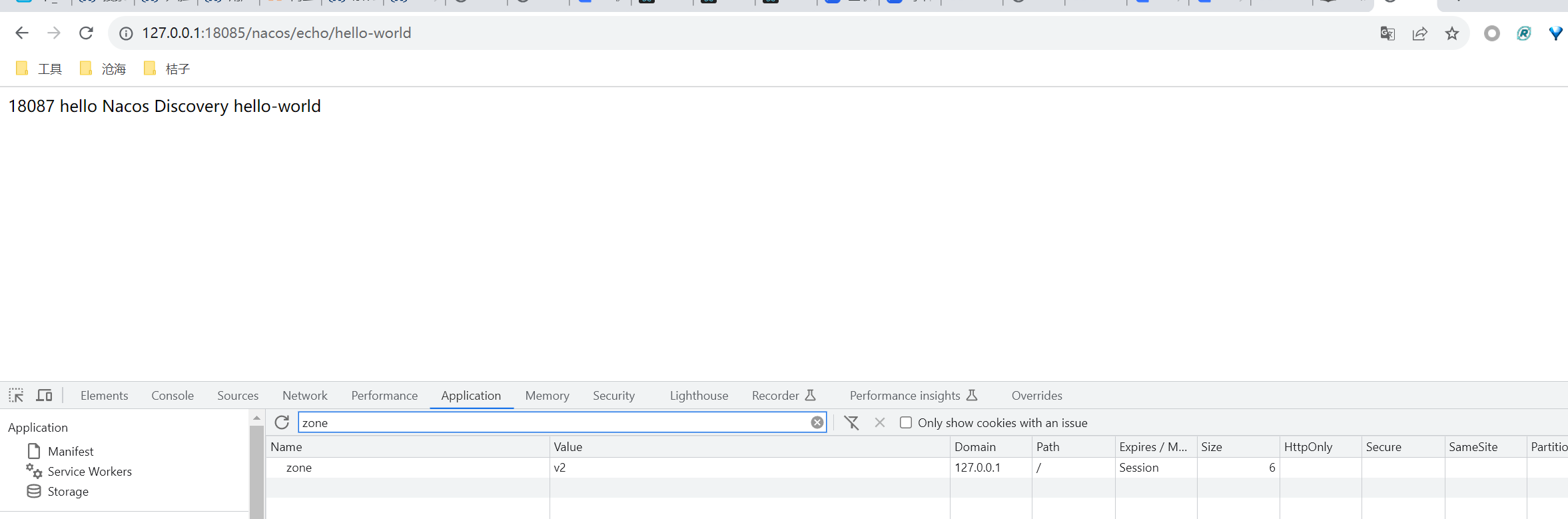
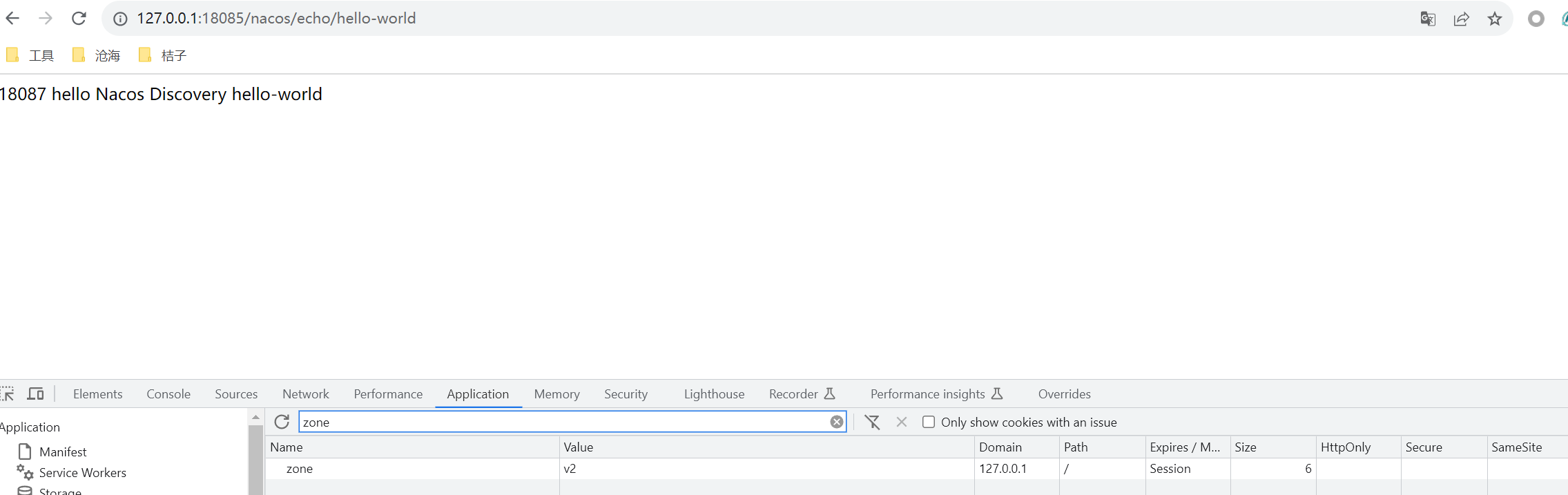
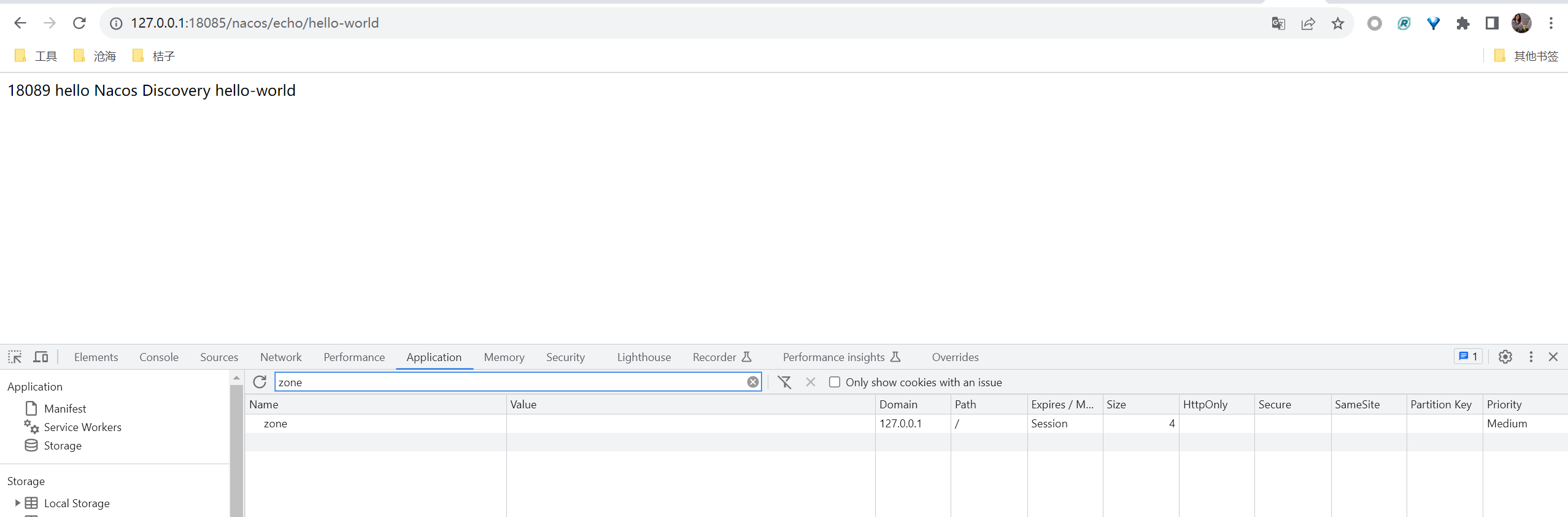
我实验后得到的优先级有:配置中心 > 命令行参数 > 本地 application.yml > 本地 bootstrap.yml
它的设计者认为,配置中心就是最高优先级的,不允许外部修改。
如果想要覆盖,可在远程配置中加下面配置
1 | spring: |
上面的说法可以在如下链接中得到验证:https://cloud.spring.io/spring-cloud-commons/multi/multi__spring_cloud_context_application_context_services.html#overriding-bootstrap-properties
3. 源码解析
org.springframework.cloud.bootstrap.config.PropertySourceBootstrapConfiguration#insertPropertySources
1 | PropertySourceBootstrapProperties remoteProperties = new PropertySourceBootstrapProperties(); |
remoteProperties 默认值:
1 |
|
org.springframework.core.env.PropertySourcesPropertyResolver#getProperty(java.lang.String, java.lang.Class
1 | protected <T> T getProperty(String key, Class<T> targetValueType, boolean resolveNestedPlaceholders) { |
当应用程序获取参数值(@Value 注解、显示调用 environment.getProperty()时)一样,environment 的查询方式是按照先后顺序查找参数值。
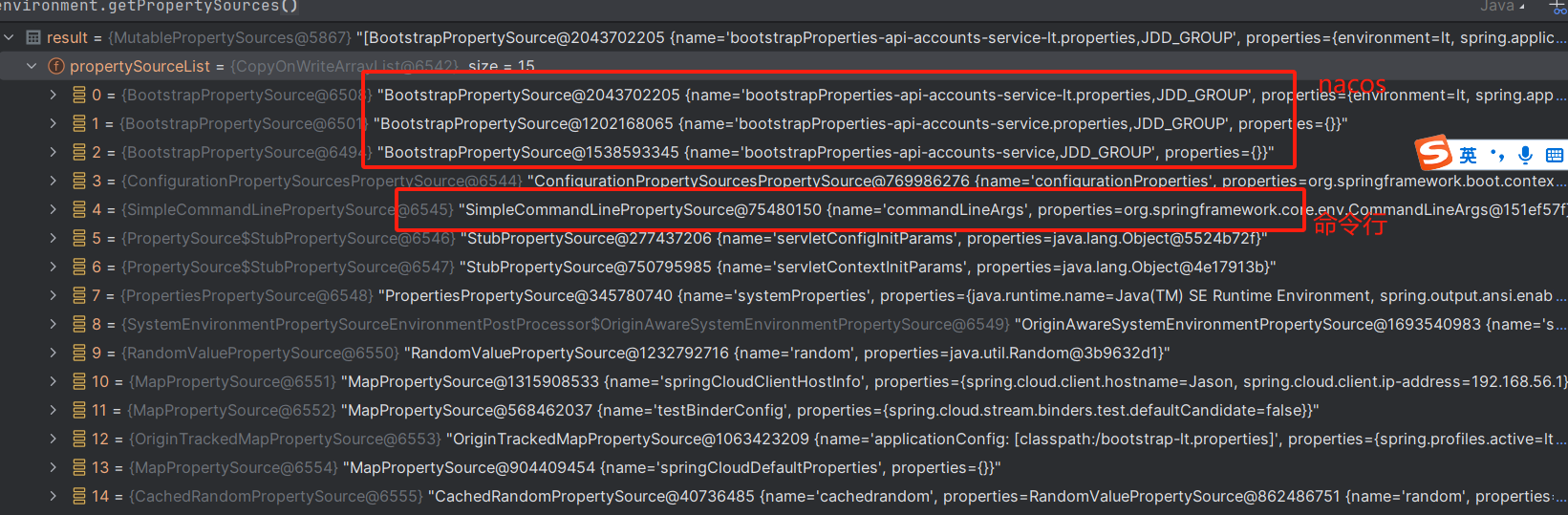
从结果上看,nacos 配置的顺序在命令之前,故 nacos 的优先级更高。