JDK全称是Java SE Development Kit .Java历经了二十几年的发展,到现在已经发布到了JDK10的版本。随着版本的改进,新的特性越来越多的加入,类似5.0引入的泛型,8.0引入的lambda和stream API都对开发有极大的效率提升,不可避免的需要对技术进行升级。同时,主流的开发框架工具spring,mybatis,maven等都会跟随jdk版本进行升级,所以需要一个开发者同时具备多个开发环境。
Do you agree to the terms of this agreement? (Y/n): y
Downloading: java 8.0.161-oracle In progress... ######################################################################## 100.0%
Repackaging Java 8.0.161-oracle...
Done repackaging...
Installing: java 8.0.161-oracle Done installing!
Setting java 8.0.161-oracle as default. $ java -version java version "1.8.0_161" Java(TM) SE Runtime Environment (build 1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode) $ sdk list java
In progress... ######################################################################## 100.0%
Repackaging Java 7.0.141-zulu...
Done repackaging...
Installing: java 7.0.141-zulu Done installing!
Do you want java 7.0.141-zulu to be set as default? (Y/n): n $ sdk default java 7.0.141-zulu
Default java version set to 7.0.141-zulu $ java -version openjdk version "1.7.0_141" OpenJDK Runtime Environment (Zulu 7.18.0.3-linux64) (build 1.7.0_141-b11) OpenJDK 64-Bit Server VM (Zulu 7.18.0.3-linux64) (build 24.141-b11, mixed mode)
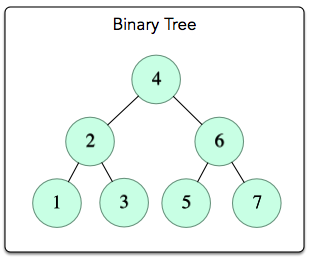
levelOrder(BinaryTree t) { if(t is not empty) { // enqueue current root queue.enqueue(t)
// while there are nodes to process while( queue is not empty ) { // dequeue next node BinaryTreetree= queue.dequeue();
process tree's root; // enqueue child elements from next level in order if( tree has non-empty left subtree ) { queue.enqueue( left subtree of t ) } if( tree has non-empty right subtree ) { queue.enqueue( right subtree of t ) } } } }
voidlevelOrder(Node root) { Queue<Node> queue = newLinkedList<Node>(); if (root != null) { // enqueue current root queue.offer(root);
// while there are nodes to process while (queue != null && queue.size() > 0) { // dequeue next node Nodetree= queue.poll();
System.out.print(tree.data + " ");
// enqueue child elements from next level in order if (tree.left != null){ queue.offer(tree.left); } if (tree.right != null){ queue.offer(tree.right); } } } }
SELECT start_date, end_date FROM ( SELECT @rownum :=@rownum+1AS rownum, Start_Date FROM Projects p JOIN (SELECT@rownum :=0) b WHERE Start_Date NOTIN (SELECT End_Date FROM Projects)) t1 JOIN ( SELECT @rownum2 :=@rownum2+1AS rownum, End_Date FROM Projects JOIN (SELECT@rownum2 :=0) b WHERE End_Date NOTIN (SELECT Start_Date FROM Projects)) t2 ON t1.rownum = t2.rownum ORDERBY DATEDIFF(end_date, start_date), start_date
booleannextPermutation(int[] array) { // Find longest non-increasing suffix inti= array.length - 1; while (i > 0 && array[i - 1] >= array[i]) i--; // Now i is the head index of the suffix
// Are we at the last permutation already? if (i <= 0) returnfalse;
// Let array[i - 1] be the pivot // Find rightmost element that exceeds the pivot intj= array.length - 1; while (array[j] <= array[i - 1]) j--; // Now the value array[j] will become the new pivot // Assertion: j >= i
// Swap the pivot with j inttemp= array[i - 1]; array[i - 1] = array[j]; array[j] = temp;
// Reverse the suffix j = array.length - 1; while (i < j) { temp = array[i]; array[i] = array[j]; array[j] = temp; i++; j--; }
// Successfully computed the next permutation returntrue; }